
在《长文:“互联网基石协议”——DNS详解》中,对DNS做了详细的介绍。今天从科来对于DNS监控的角度,来谈如何保障DNS业务的稳定和可靠。
在企业运维工作中,DNS的稳定运行至关重要,但常常面临诸多棘手问题。DNS作为域名与IP地址之间解析的核心,一旦出现故障往往事件等级高,影响范围广。
科来DNS监控方案从解决这些痛点出发,为保障DNS的稳定和可靠提供了支持。
案例:某单位精细化主动式DNS监控实践
某大型集团DNS服务覆盖内网10余个IDC机房、外网3大运营商托管节点,需支撑日均千万级解析请求。但业务扩容后,原运维模式问题显现:一是人工巡检无法实时感知DNS性能波动;二是故障后排查,MTTR超4小时,难满足业务高可用需求。
部署科来DNS监控方案后,该集团构建了完善的DNS运维指标监测管控体系,实现了对DNS业务各节点流量的实时全量采集与精细可视化监控,以及针对异常的主动告警。
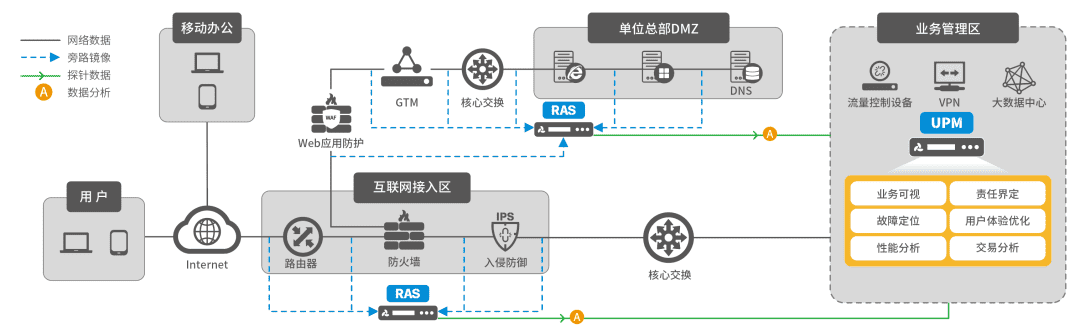
部署示意图
在某次压测中,工程师通过科来产品发现部分DNS响应情况异常,支付接口域名解析平均延迟达152ms(预设阈值≤50ms),最高延迟480ms,延迟波动幅度超300%。工程师进一步多段对比分析,发现外层负载在转发DNS请求和响应时确实出现数据包丢失。工程师由此及时进行了配置修改,从而提前避免核心DNS域名解析报错,预计规避潜在受波及交易金额达数千万元,显著降低系统风险。
建立真正面向业务的精细化智能DNS监控
DNS的稳定对于用户体验、业务安全至关重要。在稳定性建设场景中,运维团队不仅需要关注设备、CPU等基础指标,更需要结合业务视角去关注DNS服务是否对实际交易、服务产生影响,并及时采取手段。
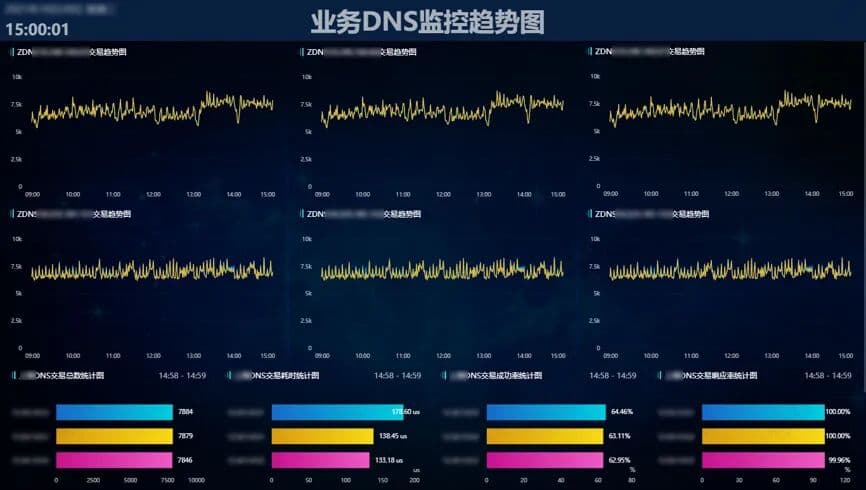
多视角呈现:从“解析失败”到“为何失败”
在稳定性高要求的领域,如金融、运营商等行业,DNS故障定位需要突破“仅知解析失败”的表层认知,更需要精准锁定异常区域与影响范围,如异常是否发生在服务器维度,是否由异常归属节点/节点硬件资源/服务配置引发,或为客户端层面故障,确定异常请求来源网段。
科来解决方案通过“多视角+明细日志”,从服务器、域名等不同视角实现对DNS服务的统计与性能呈现,还原每一笔请求交互过程,精准呈现解析延迟,同时,产品可结合网络链路数据,帮助用户更快速辨别异常根因,让故障定位处置效率大幅提升。
全天候监控+深度分析:提前感知潜在瓶颈
传统DNS运维多依赖“事后日志复盘”,无法规避突发性故障,如服务器端口异常关闭、链路闪断等。
科来全天候监控+深度分析的解决方案,以业务为中心聚焦服务效果,可以针对响应率、成功率、耗时情况等关键指标进行抓取统计,并形成高精度的趋势图标,帮助运维人员快速判断业务性能走向,提前感知潜在故障并处置。
资源优化支撑:调优运维更有依据
当某个服务器解析性能突然下降,或者DNS服务系统面临CPU使用不均衡问题,多层面的复杂交互情况往往会使得排查定位变得困难。科来全流量分析技术,能够帮助用户精准解析与DNS payload(域名、类型、TTL、响应码),还原毫秒级解析交互过程。系统可以统计不同域名的解析频次与来源区域,帮工程师找到定位异常,为DNS服务器负载均衡、节点部署提供量化依据。
科来DNS监控方案通过全链路可视、多维度溯源、数据驱动优化的能力,帮助运维团队从“被动排障”转向“主动预防”,不仅解决了DNS故障定位难、预警不及时的痛点,更通过与业务指标的联动,让DNS运维真正服务于企业数字化业务的稳定发展。